

As part of the third wave of the Canadian branch of the JRP project, we’re figuring out what types of AI tools might help us automate the data capture of the Canadian news websites included in our sites of study.
And we’re going to share the development of our process, our plan, and our code right here on this blog. Ideally, we might even be able to create a network of people working on similar projects who can all support each other.
Our goal is to capture a specific section of the homepages of our sites of study at specific times of day on each of our 14 data collection days in 2026, and automatically populate a Google Drive folder with those homepage captures. We also want to automatically generate PDFs with working links for all of the news stories those homepages display, also loaded into a Google folder (these stories will be the ones we use for content analysis). And, then, we want to generate a spreadsheet that automatically populates with the headlines, authors/bylines, and whether or not there is any mention of the use of AI in all of the news stories that are captured.
Our lead developer/code writer is Nujaimah Ahmed, who is majoring in Computer Engineering with a specialization in Artificial Intelligence at TMU – most of what you read below comes from her. But there will also be input from her project supervisor, TMU prof Ang Misri, and less technical/more process-related input from Dr. Nicole Blanchett, also a prof at TMU, who wrote this introduction.
The blog is linear – so what happened first will always be at the top, and you’ll have to scroll down to see the latest iterations of the AI tools being developed/tested/used.
Follow along on GitHub and with our documentation of our process below, and let us know if you have a suggestion or question!
PROCESS UPDATE OCTOBER 20, 2025
First Attempts at CBC Capture
- Coded a Python script that captures a screenshot of the CBC news page and saves it to a local folder directory/google drive folder
- Tested same process using already existing automated tool (Browse AI):
- Implements the same program has a UI element to visualize what is happening during capture process
- Can only capture entire page, visible part of page, or certain selections on the page
- Each capture costs 1 credit
- 50 monthly credits for free
- Different subscription tiers available if more credits are needed
| Python Script | Browse AI | |
|---|---|---|
| Pros | Can play around more with what is to be captured, until how far in the page, what components to be eliminated, etc. | No code, do not need to run a script Centralized (all captures can be done on one account and will be saved under that account)UI component with a robot assistant that can visually show what page is being loaded and captured |
| Cons | Need to run the script Could run into some automation limitations | Can’t bound until where you want the screen capture to go up to Can do 50 captures max per month |
Update Log:
| Attempt | Problem | Solution |
|---|---|---|
| 1 | Errors from website protections not allowing screen captures in “headless” mode | Adjusted browser settings to work around them without a “headless” browser |
| 2 | Only the desktop view of the news page was being captured (the visible part) | Change settings to capture the full scrollable page |
| 3 | The full page was being captured, including “My Local” and ads | Find location of “My Local” on page and create page boundaries |
| 4 | The sidebar of “Popular Now” topics wasn’t showing up | Wait longer for page to fully load, and make the image capture area wider |
| 5 | .png file was being captured instead of .pdf | Implement same script for a pdf capture |
| 6 | Browser opens on computer during each capture due to issues with running “headless” mode (CBC detects automated browsing and blocks loading of content) | Keep “headless” mode off but minimize the window immediately after launching so the browser runs in the backgroundorRun script on a virtual machine |
| 7 | pdf capture, contains full content including “My Local” and ads(Viewport crop function only available for png capture not pdf) | Manually need to delete the pages that are not required |
| 8 | Google Cloud is restricted for TMU accounts, making APIs unusable | Use a personal non-TMU account to store the captures |
Final Workflow:
- Launch Chromium browser
- Create an incognito tab
- Navigate to https://www.cbc.ca/news and wait for page to load
- Find location of “My Local” on news page and create boundaries for capture
- Capture web page as png and pdf file
- Save files to a Google Drive folder “cbc-captures”
Things done:
- Screenshot of news page up until “My Local” section
- Incognito mode
- PDF and PNG capture
Things to do next:
- Automate for daily captures without having to constantly run the script
- Automation is different for a Windows and Mac and needs to be set up on each device
- Windows: Task Scheduler, Mac: macOS Launch Agents
- Automation is different for a Windows and Mac and needs to be set up on each device
Save images to a Google Drive- Restricted access to Google Cloud on TMU account (unable to use Google Drive API) -> need to use on a personal account
- All images saved to a personal Google Drive folder “cbc-capture”
Do headless capturing (no browser opens during screen capture – happening in the background)- Headless capturing not possible due to CBC restrictions for automation tasks (block users from accessing data using automated browsers) -> automate minimizing of browser immediately after launch and automatically close after completion
PDF instead of png- PDF capturing full page instead of until “My Local” -> needs manual deletion of a few pages
- PDF capture takes more time than png (approx. 2 minutes longer)
- Kept both options for now
- Create a code-free automated solution: cloud web platform for any user to easily access (don’t need the script to run on your own computer)
Ideas:
- Central google account for captures only
- Web platform hosted on cloud
Screenshot Example:
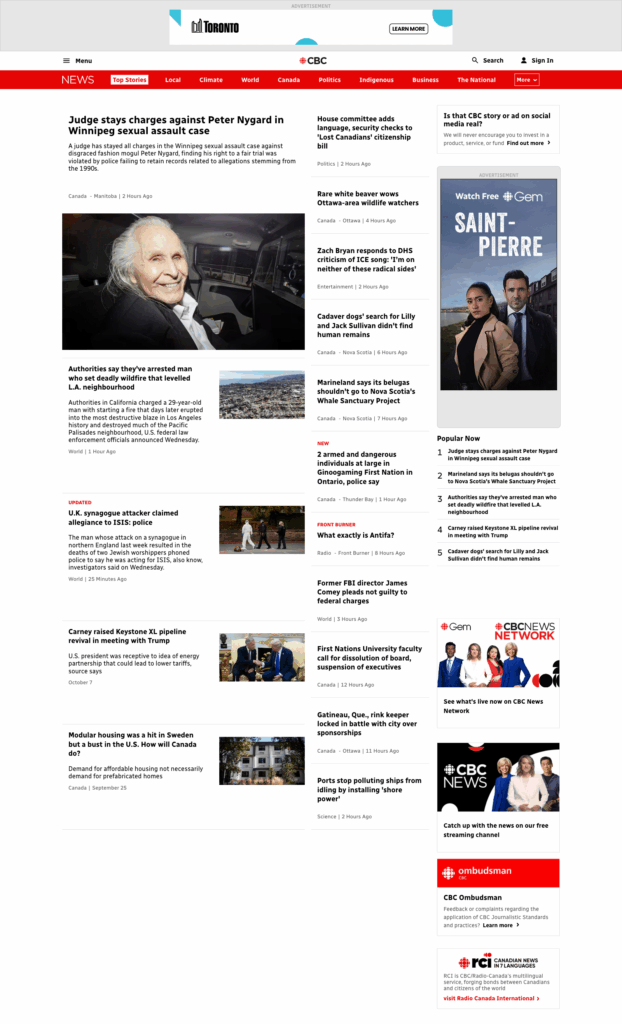
Newspaper Python package
- Multi-threaded article download framework
- News url identification
- Text extraction from html
- Top image extraction from html
- All image extraction from html
- Author extraction from text
- Google trending terms extraction
- Works in 10+ languages (English, Chinese, German, Arabic, …)
- NLP feature for keyword and summary extraction
Tests:
- Extract article urls on main page
- Extract the category that each article belongs to
- Extract title of each article
- Author and published dae errors due to CBC news article metadata
Example Output:
Title: Canada’s bet on an AI boom
Authors: [‘Cbc News’]
Published Date: None
—
Title: Democracies must remember their own values when tackling borders, says U.S. official
Authors: [‘Cbc Radio’]
Published Date: None
—
Title: Think Stonehenge rocks? Ken Follett’s new novel is for you
Authors: [‘Cbc Books’]
Published Date: None
—
Title: None
Authors: []
Published Date: None
—
Title: Mad at Dad by Janie Hao wins CBC Kids Reads 2025
Authors: [‘Cbc Books’]
Published Date: None
—
Title: Restaurants are bringing the heat as spicy dishes attract trend-chasing customers
Authors: []
Published Date: None
—
Title: Are you polychronic or monochronic? Struggling to manage your time could be due to your ‘time personality’
Authors: [‘Catherine Zhu Is A Writer’, ‘Associate Producer For Cbc Radio. Her Reporting Interests Include Science’, ‘Arts’, ‘Culture’, “Social Justice. She Holds A Master’S Degree In Journalism The University Of British Columbia. You Can Reach Her At Catherine.Zhu Cbc.Ca.”]
Published Date: None
—
Title: What was girlhood like in the early 2000s? Read these graphic memoirs to find out
Authors: [‘Bridget Raymundo Is A Multimedia Journalist’, ‘Producer Currently Working At Cbc Books. You Can Reach Her At Bridget.Raymundo Cbc.Ca’]
Published Date: None
—
Title: Librarian fired after refusing to censor 2SLGBTQ+ books wins $700K US settlement
Authors: []
Published Date: None
—
Title: 50 Years of Quirks & Quarks and half a century of science
Authors: [“Bob Mcdonald Is The Host Of Cbc Radio’S Award-Winning Weekly Science Program”, ‘Quirks’, ‘Quarks. He Is Also A Science Commentator For Cbc News Network’, “Cbc Tv’S The National. He Has Received Honorary Degrees”, ‘Is An Officer Of The Order Of Canada.’, “Bob Mcdonald’S Recent Columns”]
Published Date: None
PROCESS UPDATE OCTOBER 30, 2025
Individual Story Capture and Spreadsheet Generation
So, this week we ran into a few stumbling blocks with our AI story-capture tests.
Our goal was to capture PDFs with live links, including video and audio links. We were able to make this work on the homepage PDFs, but not the individual stories. Text links work on the individual stories – but not the links to video and audio clips.
When Nujaimah checked the HTML of the story webpages, it turned out they didn’t have links to the video embedded within the actual article, versus in the homepage where there are embedded links. Instead, the individual story pages have reference links for video and audio – which are not clickable in the exported PDFs of individual stories. To get around this, Nujaimah plans to write/run a script that goes through all the articles on the homepage, captures all playback video links, and then copies them into the spreadsheet.
The goal is to have them populate the same spreadsheet that will automatically capture headlines and authors of stories. If that works out, the video/audio links will automatically be matched up with the appropriate story in a column/row on the spreadsheet.
And there WAS some good news on the spreadsheet front. Nujaimah’s code generated a fantastic looking spreadsheet with a test capture. You can see a screen grab of it in the image below.

Other columns that might be added into this include any email addresses or social handles given for the reporter; whether the story was created by a third party/news agency; and if there is any indication AI was used in the development/writing of the story.
For more details about Nujaimah’s process read her workflow below and check out her latest code on Github.
Nujaimah’s Workflow for Individual Story Capture and Automated Generation of a Google Spreadsheet
Story Capture
Capture Process:
- Incorporate a loop in the original homepage script that gathers the links of all the stories on the homepage
- Iterate through each individual story page and capture a PDF screenshot
- Save captures to a Google Drive folder
Story Data Process:
- During the capture of each individual story gather the title, author, date published, and links to audios/videos of the story
- Copy data and paste to a Google Sheet for each story separated by rows
Update Log:
|
Attempt |
Problem |
Solution |
|---|---|---|
|
1 |
PDF capture not capturing links of audio/videos included in individual stories |
Iterate through each individual story and locate all links to playback audios/videos on HTML and copy to spreadsheet matching with the story link |
|
2 |
Newspaper python package not extracting authors (Author name is not included as part of the CBC metadata) |
Individually extract story data by locating HTML tags used for authors in the web page |
|
3 |
Third party authors not being extracted (e.g. Associated Press, CBC News, Thomson Reuters) |
In progress |
Updated Workflow (for homepage and individual story captures):
- Launch Chromium browser
- Create incognito tab
- Navigate to https://www.cbc.ca/news and wait for page to load
- Capture pdf screenshot of homepage
- Save screenshot to a Google Drive folder
- Retrieve links to all articles appearing on https://www.cbc.ca/news
- Iteratively create separate tabs for each article
- Capture a pdf screenshot and extract data (title, author, date posted, etc.)
- Save screenshots of all articles to the same Google Drive folder
- Save all extracted data to a Google Sheet
PROCESS UPDATE NOVEMBER 10, 2025
Spreadsheet generation, story capture, and collaboration
We’re making headway with the automated generation of our spreadsheets for the stories we capture, including the fix of one glitch.
We successfully – and by we I mean Nujaimah 🙂 – generated information about third-party authorship in the spreadsheet. By third-party, I mean content that is posted on one news site but was actually produced by another media organization or news agency.
However, the third-party information replaced the authors in the spreadsheet. So, now, we’re working towards making sure that both the authors and the organization the content comes from are listed if a third party is involved.
Nujaimah has also fixed an issue that came up in testing, where only one author name was being recorded when there were multiple authors in the byline. You can see what she did in her working notes below and in her code that’s available on GitHub to rectify that problem.
Our next steps include finishing up the process/methodology for capturing links for audio and video, and figuring out how we’re going to try and automate the identification of whether AI tools were used to help write/develop the story.
One issue that complicates that goal is that the terminology is not consistent across our sites of study, and news organizations in general, in identifying the use of AI. For example, AI can be referred to as robots, bots, a specific tool, eg., ChatGPT, less specifically as coming from a particular department that uses AI but doesn’t directly identify it in a story etc.
We have also identified that housing all of our captured stories is going to be a bit less straightforward than expected. Institutional firewalls prevent us from directly uploading the stories scraped with AI into any Google Drive housed by TMU. So, we’re going to pay for some extra storage using our JRP Canada account, and that is where all of the stories we collect through AI capture will first land.
Another next step will be seeing how the current capture methodology works on our French site of study, LaPresse. Nujaimah is testing that now.
And we’ll end with some exciting news! Our JRP colleagues in the U.K, working out of Bournemouth University, and Argentina, working out of Universidad Torcuato Di Tella, are going to start experimenting with our code to see if it works/how they can modify it for their own data captures.
Once they’ve done some tests, they’ll share their adventures in the comments so we can build our network of knowledge for researchers developing capture methods.
Nujaimah’s Workflow to capture authors and third-party contributions in the spreadsheet
| Attempt | Problem | Solution |
|---|---|---|
| 1 | Third-party authors not being extracted (e.g. Associated Press, CBC News, Thomson Reuters) | Modify the HTML tag used for extracting to include the full contents |
| 2 | Articles with multiple authors, only extracting the first name | Modify the HTML tag used for extracting to include the full contents |
Data Capture Workflow (for individual story captures):
- Navigate to individual story links
- Extract author(s), title, date posted, as well as additional author information (if available for third party authors)
- Populate extracted data in a Google Sheet
PROCESS UPDATE NOVEMBER 30, 2025
It’s not a linear experience 🙂
A few steps forward and a few steps back pretty much describes our capture plan for the online stories in the next wave of the JRP study. We’ve come across some issues common on all the sites we’ll be scraping stories from and some unique to specific sites.
For example, one of the things we’re trying to capture is if any AI tools are used. On CBC’s stories, AI is used to provide a “listen to this article” function. We can’t capture that information in our automated spreadsheet, though, because that explanation is in a pop-up versus part of the text of the story.
As a result, we’re just going to capture whether the term “listen to this article” appears as a way to flag that use of AI. In general, and somewhat ironically, because of all the different ways AI is used and labelled we probably won’t be able to use AI to effectively determine how AI is being used in stories – that will be up to us humans.
Another issue we’re having with the CBC capture is that we can only automatically capture one video link. If there’s more than one within an individual story, it doesn’t automatically populate onto the spreadsheet. Nujaimah’s going to keep working on it, but, for now, we’ll use human research assistants to make sure there isn’t more than one link if any video links are captured for an individual story.
On both Global and LaPresse’s sites, we can’t automatically capture ANY video links to go into the spreadsheet. For these sites, we might end up just having a “yes” or “no” column for video, and then, again, the humans will have to step in to capture these story components so we have them stored in our dataset.
Another issue we’re having is that on LaPresse’s site, our automatic capture seems to cut off at 20 stories, even if there are more than 20 stories in the bounded area we are trying to capture from. Nujaimah has tried multiple strategies to get around this – so far, no luck. But she’s continuing to work on it.
At Ang’s suggestion, Nujaimah is also going to make sure that we’re not unintentionally overwriting stories listed in a column when we’re automatically generating spreadsheets – this is something we plan on having a human testing throughout the process, even if Nujaimah determines that’s not happening now.
Nujaimah has, though, figured out how to ensure we’re not capturing the same story twice if it is appearing in multiple spots on the bounded area of the homepage. For example, if it’s in trending and latest news, or in multiple sections, such as latest news and politics, our bot will only grab it once.
Feel free to chime in via our comments section if you have any suggestions or questions about what we’re doing! And you can check out more details on the code in Nujaimah’s GitHub.
PROCESS UPDATE JANUARY 19, 2026
A bumpy ride …
Big news – we had our first data capture on Monday, January 12, 2026. Overall, it was a successful but bumpy ride. I’d also like to note that I (Nicole) like an em dash – this post is not written by AI 🙂
Now to our adventures with the capture.
We had a whole team working that night, three students organizing the data as it came in (including downloading the videos embedded in the online stories), our project manager, our coder, as well as two researchers, me and Ang. Things went off the rails pretty quickly.
When we started the capture for LaPresse, for some as yet undetermined reason, the Python Playwright package wasn’t able to extract the story links, even though it had done so previously. As a result, for all LaPresse stories, Nujaimah reverted to a more manual process, looking for website article tags on the HTML of LaPresse’s website.
We had previously experienced an issue getting the date the story was posted to load into the spreadsheet for LaPresse stories, and we thought we fixed it. But the new bugs that came up during our first capture resulted in the date issue recurring – which means Nujaimah is going to go back to the drawing board to figure out how to resolve the problem.
The Playwright package more or less worked for Global and CBC, but 16 stories were missing from the spreadsheet generated for CBC that were on the homepage (we could see them in the homepage .png capture). Three of them were videos, but the rest were text stories that didn’t populate the spreadsheet and also didn’t generate PDFs.
We ended up having to manually download each story as a PDF and input the stories into the spreadsheet. We think this is related to their location on the homepage, around the “My Local” section/how the boundaries were set up. Also, most but not all of the pictures that were in the stories appeared in the PDFs – so Nujaimah will be checking all that out, too.
For Global News, the “load more stories” boundary didn’t work. In other words, rather than stopping at the point on the homepage where it says “load more stories,” we were getting stories downloaded as PDFs and in the spreadsheet from outside the area that was supposedly bounded. Also, the order of stories didn’t appear in the spreadsheet in the order they appeared on the homepage at the time of capture. However, the story order was correct for LaPresse and CBC, even though the exact same process was used for Global and CBC. More to add to Nujaimah’s to-do list.
There was also a section of video stories from Global that were not recorded in the spreadsheet. This might be a larger issue, as seen with CBC, where stories that are video stand-alones with no text component aren’t being recognized/pulled into the capture, but it’s another thing Nujaimah will work on before the next capture.
As we were sorting all of this out in our post-capture meeting, Nujaimah and I also discussed that we’re actually using automated extraction methods, not AI methods for our capture. As she noted, though, “Anytime something is optimized, people think it’s AI.” I recognize that the fact that we’ve labelled this blog AI Methods doesn’t help with the ongoing confusion/conflation of AI and automation – something we’ve documented in other research. But, after all, effective exploration is about determining the best case uses for AI, not just using it because you can.
In our current capture, Nujiamah determined that an AI tool would be useful only if dynamic decision making was required. For example, if in every capture we were changing what websites to scrape or what data to collect, then the agent could make those decisions and run the capture for us.
It would be possible to build an AI bot to do the capture, but we’ve concluded it’s probably more work and expense than just using this automated method. So we’ll save the AI attempts for our next step in the project: content analysis for the text stories.
Previous to our first capture, we had solved issues getting multiple video links to appear from individual stories, extracting all the stories we wanted to include in our dataset at once from LaPresse, making sure the script wasn’t overwriting previous data, getting headings to appear in all of the columns on the spreadsheet, and scraping for email addresses and social handles of reporters. You can follow along with the past and present of our journey in Nujaimah’s GitHub, but there’s also a brief description of resolutions to these issues below. And we’ll update the problems/solutions identified in the capture above in our next post.
| Attempt | Problem | Solution |
| 1 | Social Media/Email links of authors are not available directly through HTML | Scrape the text in the author bio to look for any ‘@’ symbols indicating email address or social media account Scrape for any affiliated links connected to the author bio and check for social media tags (LinkedIn, Twitter, etc.) |
| 2 | Only the first few Lapresse stories are being extracted | Modify the article link pattern detector in the script to look for additional links that come in different formats |
| 3 | Video/audio links are only available after clicking on them | Simulate clicking of all buttons on each article page and extract the links that populate in the HTML after the click |
| 4 | YouTube video links are not being extracted | Modify the video link pattern detector to include YouTube links |
| 5 | Headings are not included in the sheet for capture | Check during each capture if headers are there in the first row of the sheet, and populate accordingly if not |
PROCESS UPDATE MARCH 2, 2026
Better the second time around…
It’s been a while since we’ve given an update – but we’ve been busy!
Before our second capture on Feb. 10, 2026, we had some things to sort out. Basically, the main goals were to improve the reliability of the bounding of the area we wanted to capture and ensure that the stories we wanted to show up were showing up on our spreadsheet and as PDFs for coding.
Overall, the second capture was much smoother than the first. Nujaimah’s notes on what we had to do/what we could do are below. For example, we still have to download any embedded videos separately from the PDFs of stories, but the bounding of the area we wanted to capture on the LaPress page worked much better.
Also, you’ll note below that Nujaimah refers to a “human check.” But, to be clear, we are doing a human check of everything. After the capture, RAs make sure we have all the stories we should, and then our project manager, Danielle and I (Nicole) work with RAs to select which ones will be coded. Automation is saving us time, but, so far, can’t replace the need for the nuanced understanding of humans. Now the notes:
- LaPresse
- Reduced the number of stories to be captured to a set number (33) – after doing multiple tests, it was found that the stories on the homepage do not go beyond 32, so this number can be preset
- There may be 1 extra story on the Google Sheet, which is not on the home page (the very last row). I’ve done this in case there is an extra story here and there to account for it
- Date format is now fixed and is extracted (Lapresse had changed it again the night of January capture, causing the issues with the date for that capture)
- Lapresse has changed the homepage section names – “Pouvoir D’achat” is no longer included so I’ve bounded to “Les Plus Consultes”
- Reduced the number of stories to be captured to a set number (33) – after doing multiple tests, it was found that the stories on the homepage do not go beyond 32, so this number can be preset
- CBC
- All links to featured videos with the title and date from the homepage are captured now, this includes in the featured videos section – they are appended to the last rows of the Google Sheet
- There are no authors for these videos, just video links and dates
- There may be duplicate video links that were captured as feature videos if they correspond to a story article – this needs a human check
- All stories are captured – none missing
- All the content is loaded – sometimes there are empty blocks, but this is not the actual content of the article (all text, images, videos are in the PDF)
- I added extra wait time for the page to load before capture in case
- All links to featured videos with the title and date from the homepage are captured now, this includes in the featured videos section – they are appended to the last rows of the Google Sheet
- Global News
- Featured shorts cannot be captured – embedded within a video player that does not give access to the actual links to the shorts
- The stories captured are now correctly bounded now until the “Load More” section – for both Google Sheets and PDFs
- Captures are done one-by-one – similar to how CBC and Lapresse were done (data should populate now one-by-one instead at once at the end)
- Stories are now in order by section
- Videos from the “Video” section are captured and appended to the end of the Google Sheet – no authors for these, just video links and dates
- Things we can’t fix:
- Global News:
- Two stories are always out of order from the last section – this is due to Global News DOM and the way they put the locations of the stories in the sections – two of them are always in the wrong section -> need human check
- For any live stories, the date needs to be manually entered – not capturable until the live story is over – it shows as “no date found” (for other sites it shows last update and time range eg. 1 hour ago)
- Global News:
So, that’s the latest. Remember, you can always check out Nujaimah’s GitHub if you want a closer look at the code.
Next capture date is in a couple of days — fingers crossed we’re on a roll!